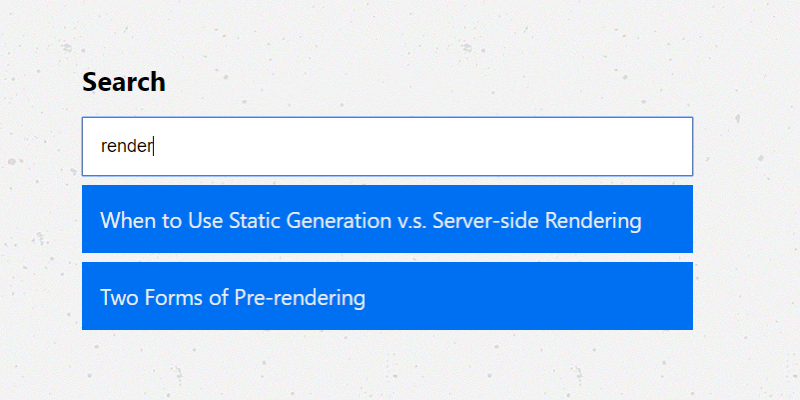
Building a search component for your Next.js markdown blog
JournalHow to build and integrate a search component into a markdown-based blog with Next.js
Next.js is a React framework that includes many out-of-the-box features available, such as routing, code-splitting and server-side rendering.
In version 9 (nextjs.org/blog/next-9), API Routing was introduced to the framework — making it easier than ever to introduce API endpoints to a Next.js application.
The official website provides an example tutorial, covering the fundamentals of the framework— showing you how to build a markdown blog in Next.js.
In this article let’s take a look at how to build upon the Next.js example application, extending the functionality by integrating a search component.
Let's get started
To begin with, we need to create a new endpoint for our search API. To do so, let’s create a new file: /pages/api/search.js
export default (req, res) => {
res.statusCode = 200
res.setHeader('Content-Type', 'application/json')
res.end(JSON.stringify({ results: [] }))
}API routes must be placed within the /pages/api/ directory, as Next.js understands that these routes will be API based.
With this now in place, we can access http://localhost:3000/api/search within either the browser or a tool such as Postman, and receive our empty JSON payload { results: [] }
For API requests, Next.js exposes the following parameters:
request
An instance of http.IncomingMessage, plus some pre-built middlewares
response
An instance of http.ServerResponse, plus some helper functions
Loading post data
Now that we have a basic scaffolding of our API endpoint in place, we need to load in our post data.
Next.js pages allow us to use getStaticProps or getServerProps to dynamically include data such as markdown content within our application pages (getStaticProps will run at build time and pre-cache the data — whereas getServerProps will execute on each page request).
API routes, however, do not have access to such helpers.
So, when we receive a request to our search API endpoint — how can we access an up-to-date list of our blog posts to filter by our search query?
An option that presents itself is to create an javascript module containing an array of objects representing our post data, that the API endpoint can consume at runtime.
Caching posts
To create the array of posts, we need to cache our posts. We will need to write a small script that will create an array of post data, and save this to a file that can be imported by the endpoint.
const fs = require('fs')
const path = require('path')
const matter = require('gray-matter')
function getPosts() {
const postsDirectory = path.join(process.cwd(), 'posts')
const fileNames = fs.readdirSync(postsDirectory)
const posts = fileNames.map((fileName) => {
const id = fileName.replace(/\.md$/, '')
const fullPath = path.join(postsDirectory, fileName)
const fileContents = fs.readFileSync(fullPath, 'utf8')
const matterResult = matter(fileContents)
return {
id,
title: matterResult.data.title
}
})
return JSON.stringify(posts)
}
const fileContents = `export const posts = ${getPosts()}`
try {
fs.readdirSync('cache')
} catch (e) {
fs.mkdirSync('cache')
}
fs.writeFile('cache/data.js', fileContents, function (err) {
if (err) return console.log(err)
console.log('Posts cached.')
})This file, when executed, will gather the contents of our markdown posts folder, generating an array of objects, each representing a blog post — including the post ID and also its title.
Then, it check's if our cache folder already exists, and if not, creates one. Following this step, our posts cache is written to cache/data.js as a constant that can be imported by our API endpoint.
For now, let's run this script manually via node cache/data.js.
As you will see, our new cache folder & file is created, which we will be able to later import to our API endpoint, making our post data accessible.
However, this workflow is far from ideal — where we’ll need to remember to run this command each and every time we add a new blog post — otherwise, our cache, and as such our search component, will be out-of-sync and missing new posts from the results.
Husky pre-commit hooks
To automate the caching process, let’s make use of git hooks.
Git hooks can be configured to run when a git command is executed, such as when we commit a new blog post — which is a perfect time to flush & recreate our cache file.
To create our git hook, we will the package husky, which allows us to set-up and maintain git hooks incredibly easily via our package.json file.
First, run yarn install husky to add the package to your repository. Second, add the following lines to your package.json file:
{
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"cache-posts": "node scripts/cache.js"
},
"husky": {
"hooks": {
"pre-commit": "yarn cache-posts && git add cache/data.js"
}
}
}Simple :) Anytime we now commit changes to the git repository, our pre-commit hook will run, and update our cache automatically.
Search API Response
Finally, now that our post data is accessible and maintainable, we are able to add some functionality to our /api/search endpoint:
import { posts } from '../../cache/data'
export default (req, res) => {
const results = req.query.q
? posts.filter((post) => post.title.toLowerCase().includes(req.query.q))
: []
res.statusCode = 200
res.setHeader('Content-Type', 'application/json')
res.end(JSON.stringify({ results }))
}When the /api/search endpoint is called, we check for a query parameter q, and if present, we create an array of post items where the query is included in the post title.
For the sake of this example, the search functionality is implemented using a simple array filter combined with toLowerCase() and includes(), however — I would suggest using such a package such as github.com/wouter2203/fuzzy-search for a better end-user experience.
The code above works great for production builds, but in development mode, the cache may become out of sync with current unstaged changes.
When Next.js runs in development mode, the API routes will execute server-side, and as such, we can use getSortedPostsData() from lib/posts.js to retrieve an up-to-date list of posts data.
import { getSortedPostsData } from '../../lib/posts'
const posts =
process.env.NODE_ENV === 'production'
? require('../../cache/data').posts
: getSortedPostsData()
export default (req, res) => {
const results = req.query.q
? posts.filter((post) => post.title.toLowerCase().includes(req.query.q))
: []
res.statusCode = 200
res.setHeader('Content-Type', 'application/json')
res.end(JSON.stringify({ results }))
}Search component
Now that our API endpoint is working correctly in both development & production modes, the final step is to introduce a new component, Search.
To demonstrate the search API — our new component will generate a search box that calls our API and lists a set of results matching the search query.
import { useCallback, useRef, useState } from 'react'
import Link from 'next/link'
import styles from './search.module.css'
export default function Search() {
const searchRef = useRef(null)
const [query, setQuery] = useState('')
const [active, setActive] = useState(false)
const [results, setResults] = useState([])
const searchEndpoint = (query) => `/api/search?q=${query}`
const onChange = useCallback((event) => {
const query = event.target.value
setQuery(query)
if (query.length) {
fetch(searchEndpoint(query))
.then((res) => res.json())
.then((res) => {
setResults(res.results)
})
} else {
setResults([])
}
}, [])
const onFocus = useCallback(() => {
setActive(true)
window.addEventListener('click', onClick)
}, [])
const onClick = useCallback((event) => {
if (searchRef.current && !searchRef.current.contains(event.target)) {
setActive(false)
window.removeEventListener('click', onClick)
}
}, [])
return (
<div className={styles.container} ref={searchRef}>
<input
className={styles.search}
onChange={onChange}
onFocus={onFocus}
placeholder="Search posts"
type="text"
value={query}
/>
{active && results.length > 0 && (
<ul className={styles.results}>
{results.map(({ id, title }) => (
<li className={styles.result} key={id}>
<Link href="/posts/[id]" as={`/posts/${id}`}>
<a>{title}</a>
</Link>
</li>
))}
</ul>
)}
</div>
)
}The search component makes use of several React hooks, alongside three key event handlers:
onChange
Listen for changes in our search input field, update the query state, and if there is a value - call the API to request a list of results matching the query. The example here to listen and make a request is a simple implementation using the native fetch API. For further optimisation, the event listener could be throttled to not make requests on every key change, and also integration with the AbortController could be added, to cancel any requests in progress when a new key change is made.
onFocus
When the input field is focused, set the active state to true to display our results - and, bind the onClick event listener to the window.
onClick
The onClick event listener checks the users click, and whether this is inside or outside of the search results. If outside - we update the active state value to false to hide our search results. When true - we do change nothing, which allows the native click handler of the <Link> component to navigate the user to the relevant blog post.
Summary
I hope this article has shown some interesting techniques available to implement a search component within a Next.js markdown blog, and also perhaps some techniques that can be applied to other areas of your application development also!
Demo nextjs-blog-search-api.now.sh
Github: github.com/matswainson/nextjs-blog-search-api
You may have noticed some similarities between the getPosts method introduced in this post, and the getSortedPostsData function in lib/posts.js module.
Both methods have similar code, and it would of been cleaner/less code to import getSortedPostsData into the cache script and then mutate it's response.
However, node will execute our cache script as a CommonJS module, whereas lib/posts.js is written as an ES module. There is an experimental node feature available to execute scripts as ES module, however this will require changes to our application environment setup, which can break Next.js build scripts. As such, there is an acceptance made for this approach to keep the application stable.